Deployment to Production
Since version 2.9.0, the Olympe platform supports deploying new versions without downtime for the end-users. This typically applies to applications developed on a codev environment to be deployed on a production environment.
This feature is based on a blue-green deployment feature which allows to keep the previous application running until the new version is ready for use.
Prerequisites
To use the no-downtime deployment feature, you need to have the following setup on your environment:
- The environment on which you need to deploy a new version of your application must run on version 2.9 or higher of Olympe.
- Production mode must be activated in the config file of all your deployments: backends and frontend.
{"sc.production": true}
- The no-downtime option and additional services must be activated in the config of your environment (see below).
Activating No-downtime deployment on your environment
- Make sure that your environment uses the version
2.4.0or higher of the Olympe Chart and2.6.0or higher of the Olympe Internal Chart (see inChart.yamlfile of your config). If not, ask the Olympe team to update your environment. - In the public chart
olympe, the following values must be set totruein thevalues.yamlfile:olympe:additionalServices:enabled: trueadditionalIngress:enabled: true - In the internal chart
olympe-internal, the following values must be set totruein theinternal.yamlfile:This option changes the configuration of your namespace: the traditional kubernetes deployments (the orchestrator, the backends and the frontend) will be replaced by rollouts. A rollout is a kubernetes resource that manages the deployment of a new version of an application: combined with ArgoCD, it is designed for blue-green deployments: when a new version of the container image must be deployed or any configuration entry changes, the system boots a new pod in parallel and keeps the previous ones running. It allows the developer to validate the behaviour of the new version before unloading the old one.olympe-internal:noDowntimeDeployment: true - In the configuration of the deployment pipeline of your environment (e.g.:
<my-env>.yamlin theClientsproject on Gitlab), the following values must be set:Theolympe:projects:<project-name>:instances:<environment-name>:noDowntimeDeployment:enabled: true # to enable the no-downtime deploymentpromotionMode: manual # or autopromotionModevalue can be set tomanualorauto. If set tomanual, the pipeline will wait, after deploying the rollouts, so that you can test your application before promoting them and finish the deployment. When ready to continue, simply resume the pipeline. If set toauto, the promotion is done automatically at the end of the deployment pipeline.
Impacts of having rollouts instead of deployments
As explained before, a rollout behaves differently than a deployment: it does not replace the existing pods but creates new ones and waits for an external confirmation to replace the old ones. This confirmation is called promotion in the ArgoCD interface.
Therefore, whenever a new container image of a backend, frontend or orchestrator is published and triggers a deployment pipeline, it creates a new rollout of that image. The rollout waits until being promoted to replace the existing pod. The two common ways to promote the rollout are:
- Wait for the
code as datadeployment pipeline which ends by the rollout promotion step: waiting for manual confirmation or automatically according to the config. The pipeline looks like this: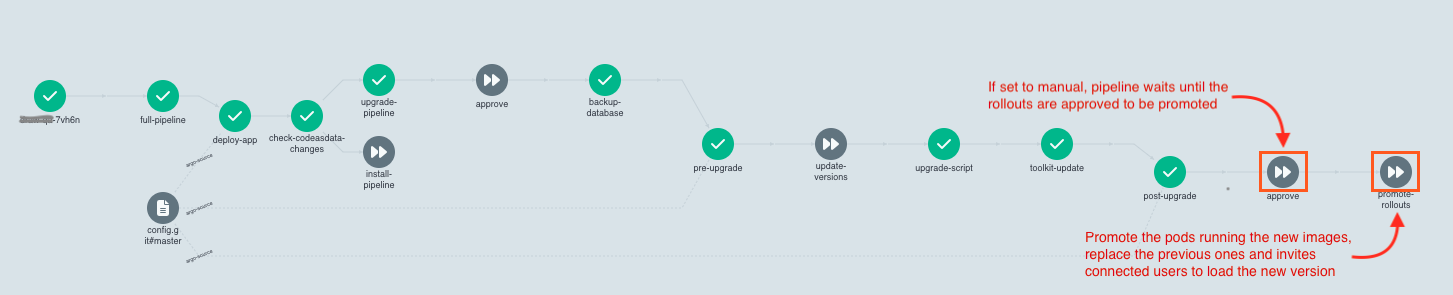
- Go to the ArgoCD interface of your application and promote the rollouts manually one after the other. Check on the left side to display the list of suspended resources and promote them one by one.
Since any change in the configuration generates a new rollout, if you change the oConfig value of a component of your application or any other configuration aspect of it, a new rollout is generated and must be promoted to be used.
Impacts on the application
In the public chart, you had to activate some additional services. They are used to manage the traffic between the old and the new version of the application: when the rollouts are waiting for promotion, you can access them to test the new version of the application while the actual users still access the old version. To access the new version of the application, use the following URL: https://preview.<usual-hostname>/<path>.
Backends are also working in that way: UI Application opened via the preview endpoint communicates with the new version of backends while the previous backends are still serving requests coming from actual users.
Impact for users using frontend applications
At the end of the code as data deployment pipeline, when the rollouts are promoted, running frontend applications trigger the onUpgradeDone event. By default, if not override, users will see the following popup:
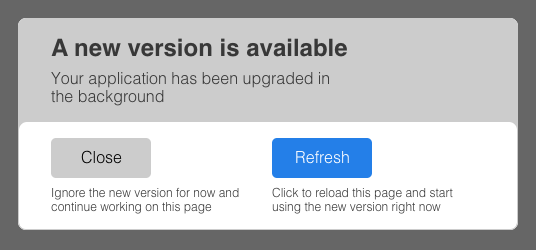 .
.
This behaviour can be overridden by implementing the onUpgradeDone event in the UI application properties, within Draw (e.g.: to force the application reload, customize the popup design, etc.).
Managing the New Version of the oConfig for Frontends or Backends
It may happen that when you switch from version A to B of your application, the configuration of the application must be updated. In that case, you must update the oConfig of your application.
In order to prepare the new configuration before deployment and make it available for the next backend/frontend image deployed, you can now define multiple oConfig entries and decide which one is active and should be used next time:
olympe:
serviceApps:
<backend-name>:
oConfig:
current: "v1"
next: "v2"
configs:
v1: |
{
"sc.production": true,
"param1": "a value"
}
v2: |
{
"sc.production": true,
"param1": "another value",
"param2": "a new value"
}
This example shows how to manage the configuration of a backend named <backend-name>. The current value is the active configuration and the next value is the configuration that will be used for the next deployment. The configs array contains all the configurations that can be used by the backend. The configs array must contain at least the current and next configurations. If the next configuration is the same as the current configuration, no changes will be applied during the next deployment.
This feature works independently for each service app declared in the configuration as well as for the frontend.
The oConfig as a single string value is still supported. If you don't define the current, next and configs entries, the oConfig will be used as before.
Roll back in case of issue
If you encounter any issue when testing your application in preview, after the deployment, and before the promotion of rollouts, you have the ability to roll back to the previous version while keeping the previous application running during the whole process:
The deployed backends, frontend, code-as-data and orchestrator are based on versioned docker images. So the target is to roll back these versions to the previous ones or equivalent and deploy them again. The easiest way to do so is to revert the commit, on your git repository, that generated the deployment: since this is a production environment, most of the time it correspond to a merge commit that bring all the changes from development to production.
When the commit is revert, be sure you generate the 3 (or more) images you need to change all the pods of your environment (backends, frontend and code-as-data). A new deployment workflows will be triggered and deploy the old code as data, potentially change back the orchestrator and toolkit according to the version of the platform.
When the workflow is done, you can access your newly deployed old application and test it using https://preview.<usual-hostname>/<path>. Check that everything works fine as it was before the bad deployment.
Finally, don't forget to manually end the workflow by promoting the rolled back pods.
Do not forget to cancel or terminate the previous pipeline you let unfinished on workflows.olympe.io so it does not wait forever to terminate the pipeline.